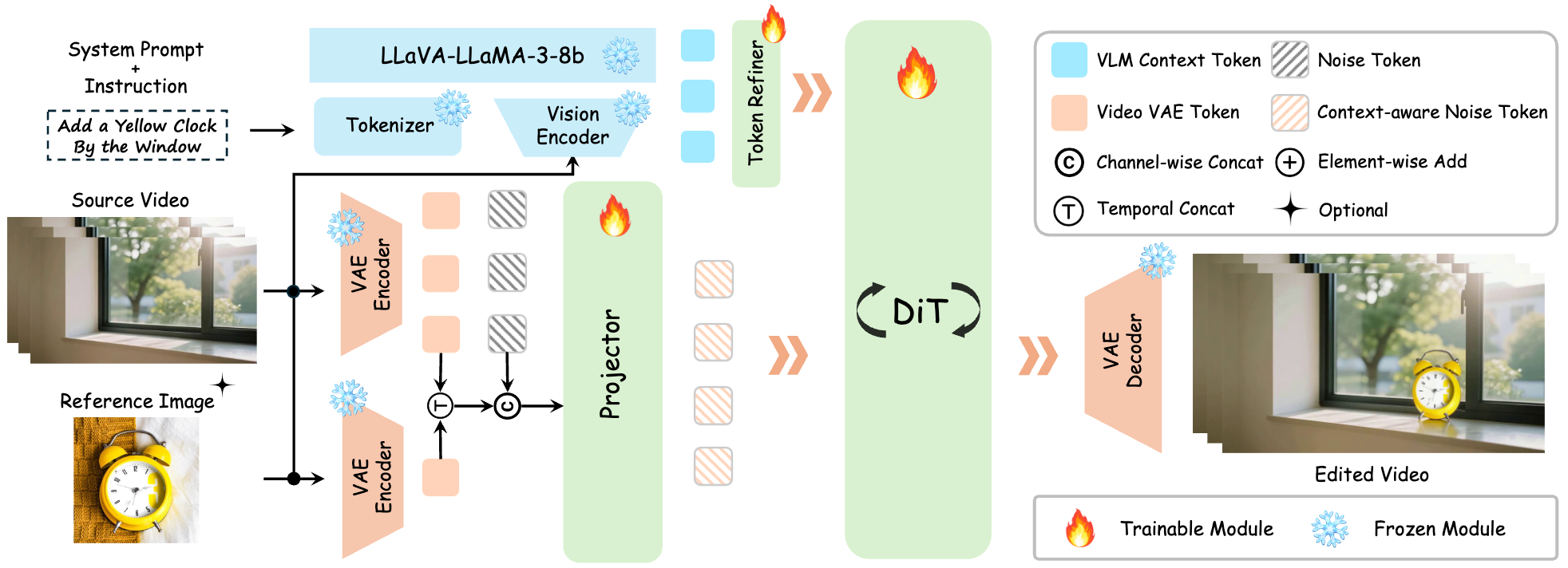
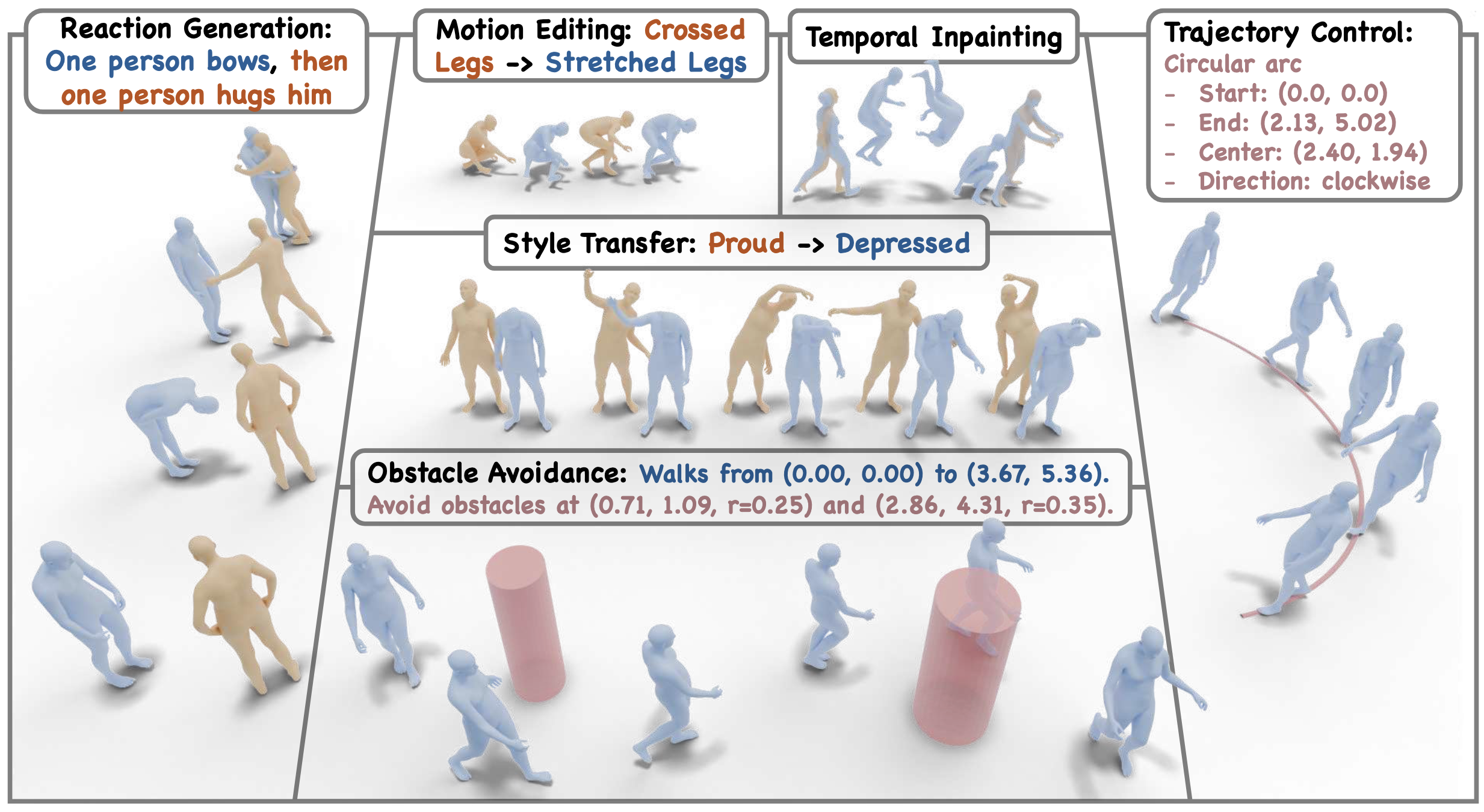
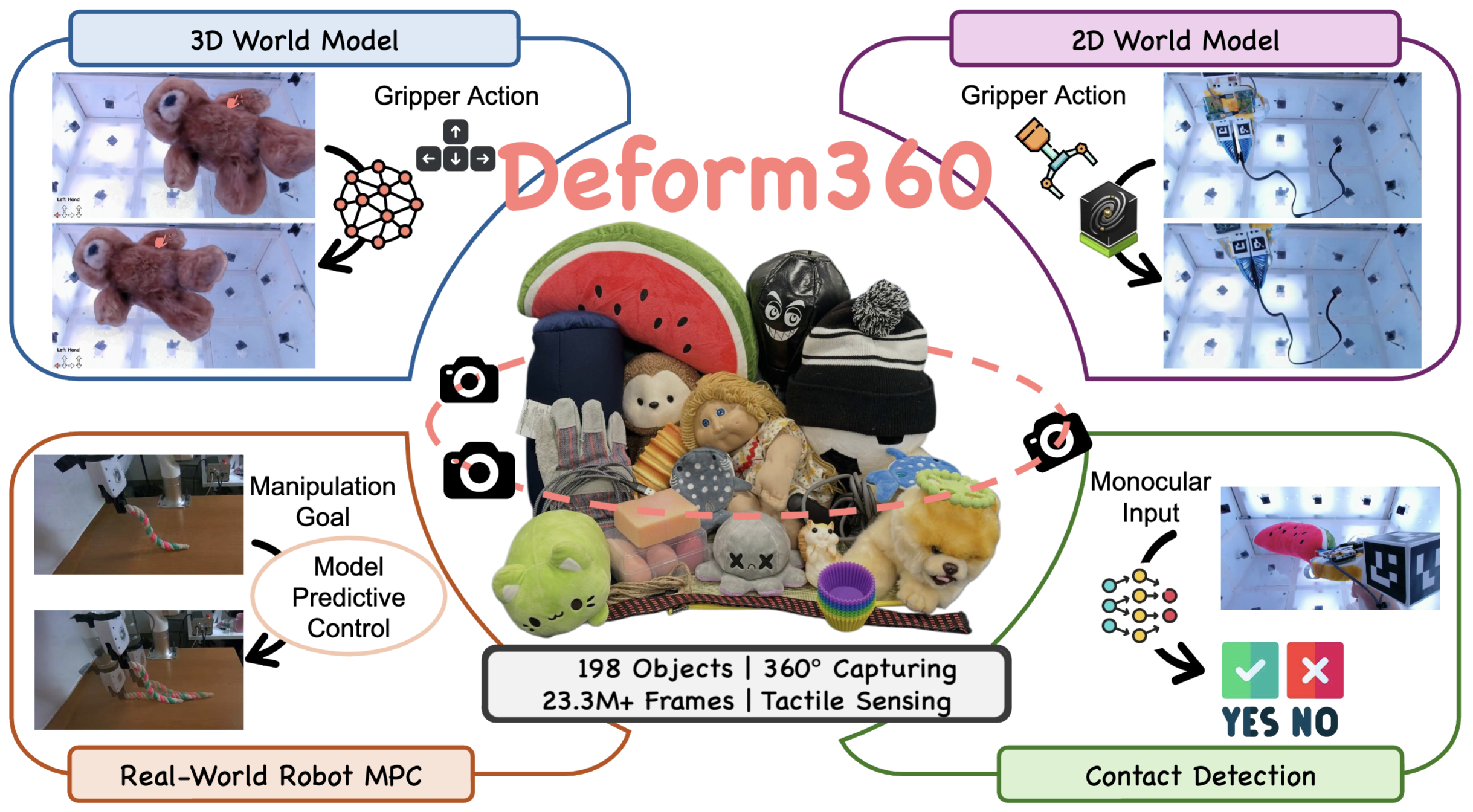
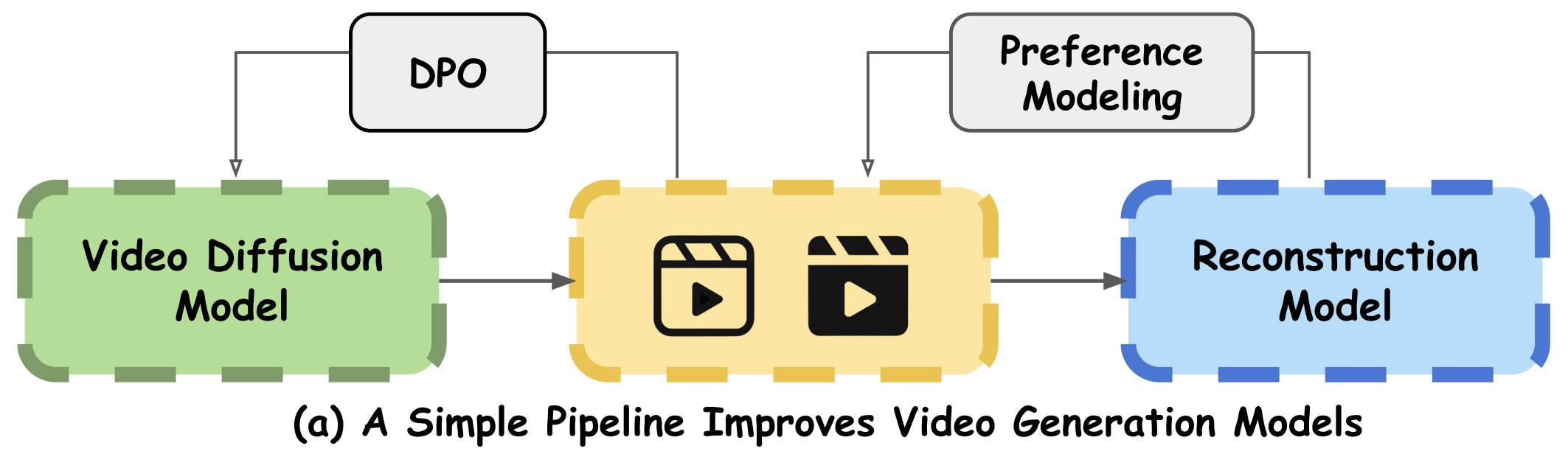
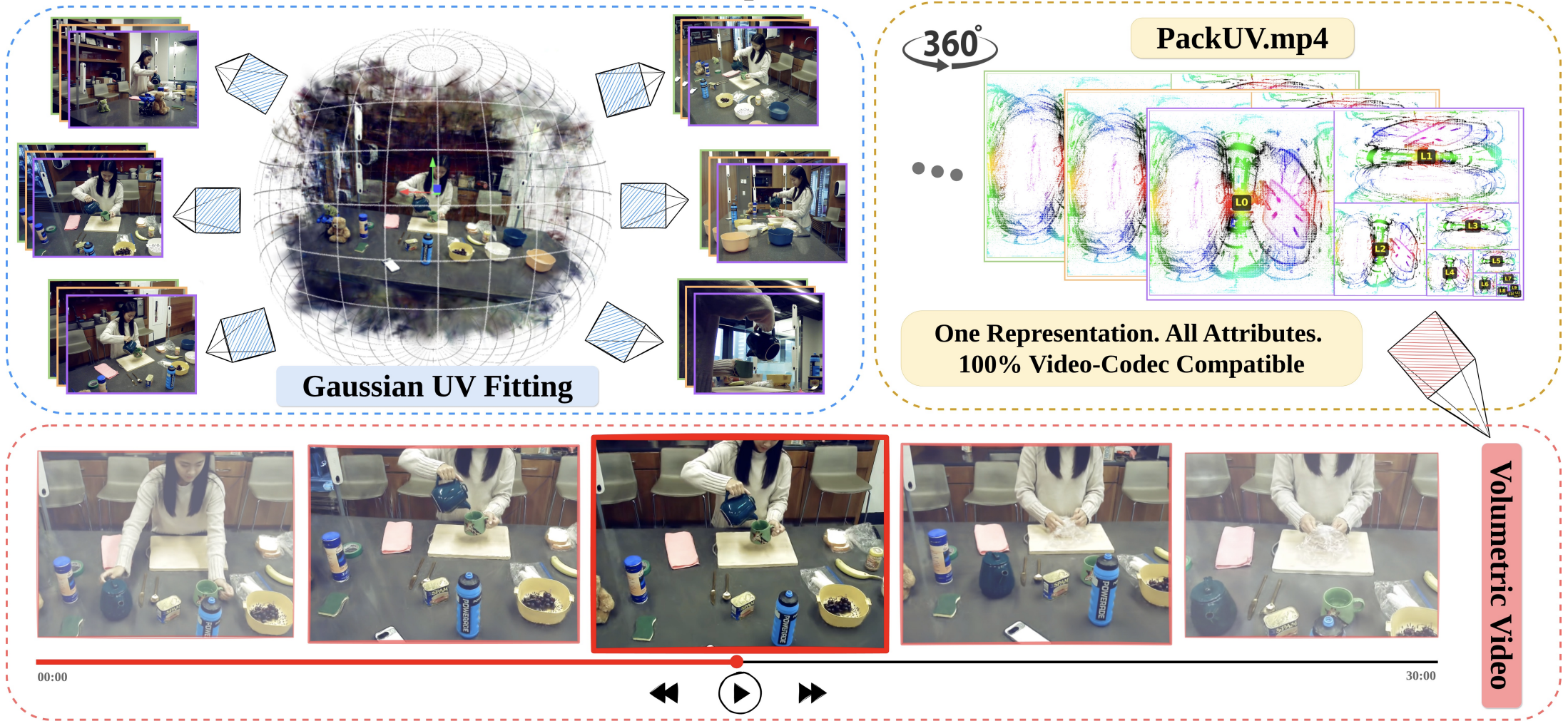
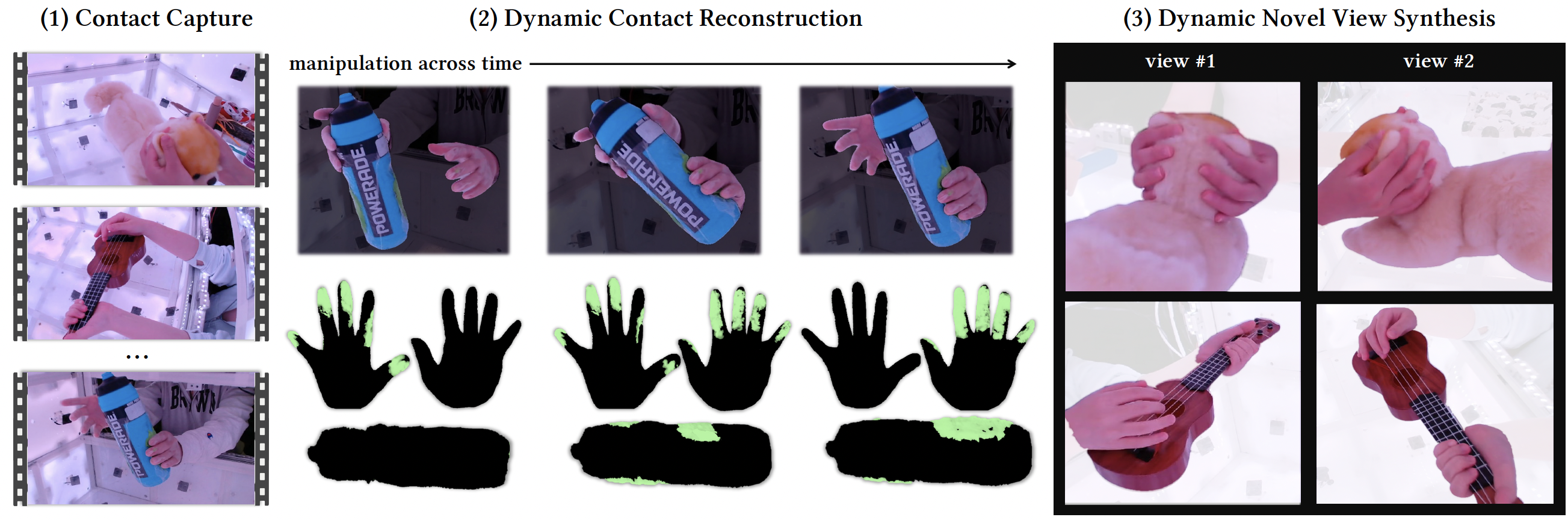
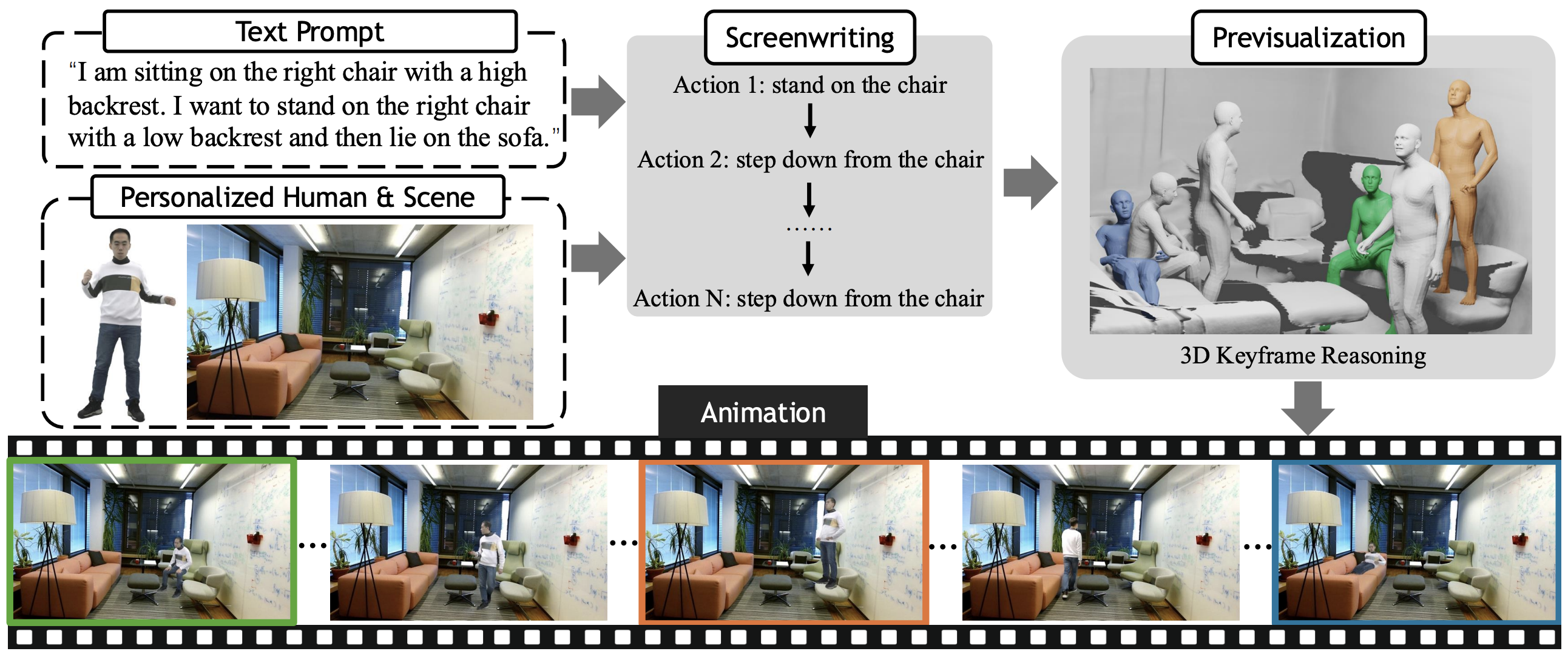
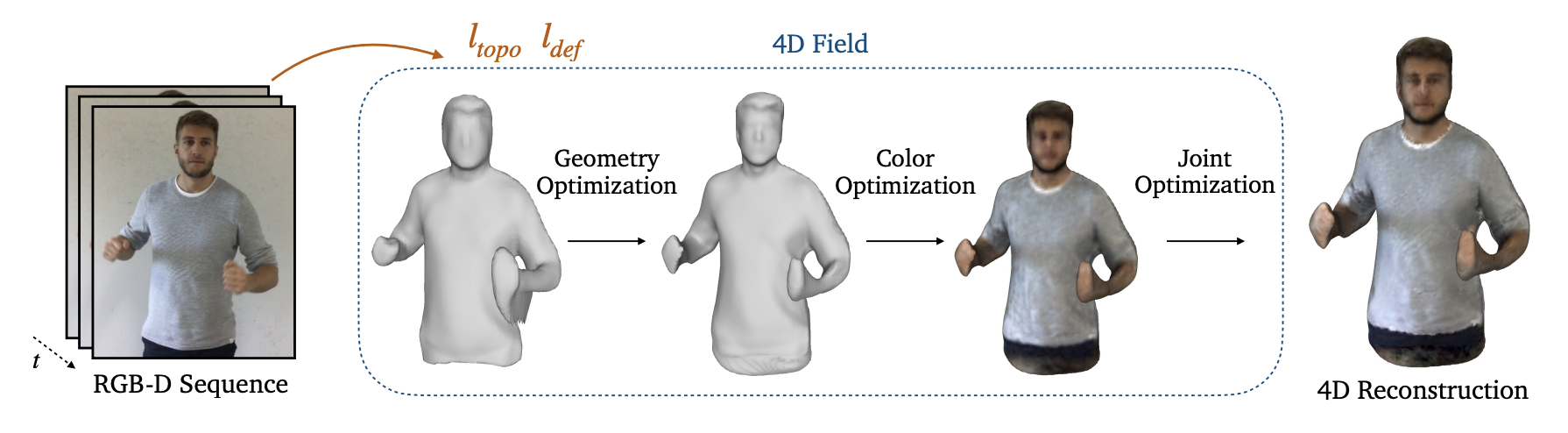
28th June 2024
Xiaoyan Cong 丛箫言
Email: xiaoyan_cong [at] brown [dot] edu
I am currently a 2nd-year CS Ph.D. student at
 Brown University, advised by
Prof. Srinath Sridhar.
I obtained my B.E. of Robotics Engineering from
Brown University, advised by
Prof. Srinath Sridhar.
I obtained my B.E. of Robotics Engineering from
 Zhejiang University
with honors from Cho Kochen Honors College in 2024.
During my undergraduate, I am grateful to be advised by
Prof. Qixing Huang,
Prof. Li Yi,
Prof. Qifeng Chen.
Zhejiang University
with honors from Cho Kochen Honors College in 2024.
During my undergraduate, I am grateful to be advised by
Prof. Qixing Huang,
Prof. Li Yi,
Prof. Qifeng Chen.
I'm always open to collaboration -- please contact me without hesitation!
I am currently looking for a research internship for 2027. Please reach out if you find I could be a good fit for your team!
 WeChat
WeChat